Building a Political Media Research Platform
- 8 mins2016 was a watershed year in American politics. It was a watershed year for me too, but all the details are too big for the scope of this post. But suffice to say it opened the eyes of many (including mine) to the power of data to manipulate social movement.
Not too long after, I became professionally involved in leading the development the data infrastructure for political campaigns and organizations. One of my first projects, and what was soon to become my main project, was building the tools for automatic capture and analysis of political advertising data. I never really attempted to collect all my thoughts and lessons learnt from building the research tools, so I’ll try to do so now.
Building an accurate data intelligence pipeline


Capturing digital political advertising data required building a realtime data collection pipeline that scraped public advertising transparency reports from Facebook, Google, Snapchat, and others. Unlike a traditional data pipeline where many variables can be controlled for, a web-scraping pipeline suffers from the following downsides:
- Data on a website changes on an indeterminate schdule
- Changes to web pages cause previous information there to be lost
- Changes to how data is presented
- You can be ratelimited without warning
- Authentication to access data can be through a UI
- Data you collect can be incomplete
Solving for all of these issues requires a careful attention to detail, as well as some creative adaptation of traditional data engineering best practices. And a lot of work! 
Data scheduling
The answer is simply you need to find the assumptions you can safely make, be prepared to collect a ton of data, and to be able to catch and adapt from your failures.
As an example the Facebook Transparency Reports make CSVs of daily data available on most days. This is can usually be collected once a day, but if missed on the date of publication, can’t be accessed historically. In addition, their ad-level reporting updates indetermiately. This required running multi-threaded web scrapers so that we could scrape each ad at least once a day.
Changes to Website structure
This is pretty similar to traditional data pipelines in that you need to be able to detect when a data source is down, or if the pipeline is not exporting outputs properly. You need canary tests that will trigger if no data is being collected over a certain point in time. You also need to log errors or missing data so you can trigger an alarm if missing data counts go over a certain threshold.
Data Access
There is exist fairly decent rights when it comes to collecting data from public webpages. This has unfortunate consequences for individuals who may not be anticipating that their Facebook photos are being used in large-scale computer vision and surveillance projects. But as long as it is open-season, it also applies to corporations and the content on their websites.
However, they unlike individuals, have the ability to shut you down so you need to be careful. Even when not provided, you need to determine respectful limits for how often you are querying webpages.
Finally you may have to authenticate using a UI process built for a human user. 2FA can be handled by automating the relevant protocols whether it is SMS or OTP (rotating numbers). I used Tossable Digits and PyOTP to handle the authentication.
Incomplete and inaccurate data
The biggest issue for any web scraping project is making sure your data is complete – and knowing when it isn’t. This is issue is big enough that I would discourage web scraping for most projects with serious goals. You are basically trying to reverse engineer a dataset. 100% of the time, it is better to get access to the actual dataset. But if you have 0% chance of getting access to it and decide to go the web scraping route, you need to have a way of testing your data to make sure it is accurate and complete.
To give an example of the problem, consider that the Facebook Transparency Report offers ad level data. However, metrics such as ad spend and ad reach are bucketed in fairly fuzzy bucket amounts. So if you are trying to evaluate the daily spend on an ad, it is impossible from just looking at what Facebook provides at the ad level. In addition, Facebook offers no history of the spend – you have to build that history yourself with daily web scraping.
However, Facebook also provides exact daily ad spends at the advertiser level. So by collecting those you can know the daily spend for all ads for an advertiser.
All this gives you enough data points to estimate the actual daily spend of an advertisement on Facebook. You just have to ensure that you are collecting one data point per day, per ad, as well as the daily spend of an advertiser per day. You can use the date of when an ad spend bucket changes to know when it has hit a minimum of spend. And using the advertiser level spend you can distribute the estimated spend among all the active ads that day.
Finally, if you are running your own ads, or know someone that is. You can double check against the real numbers. And thus be confident in your own estimates.
Political Advertising Analysis
When not to use AI
I’m a big believer in not using more than what you need. Plenty of times I’ve seen attempts to use the latest AI or machine learning techniques to build a predictive model that then works less well than a basic technique such as linear regression. The linear regression is also easier to build. But it doesn’t sound as fun as chasing the buzzwords.
On this project I had a data engineer who attempted to build a machine learning model that would automatically categorize ads into categories as well as predict the emotional content of the ad. They utilized paid data labelers and volunteers from the team to code the training data. It was an ambitious project that ultimately failed because to build the perfect model with so many parameters to predict, you need a very large amount of training data, more than what was available.
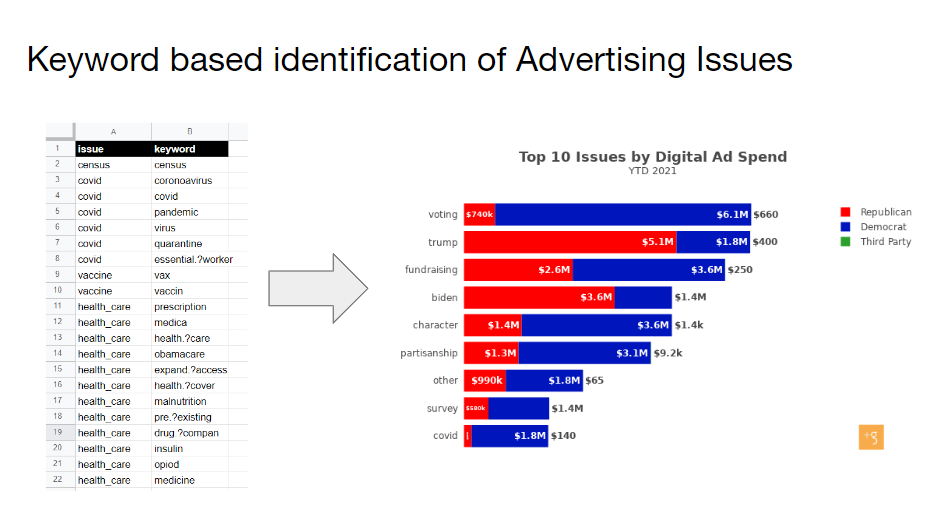
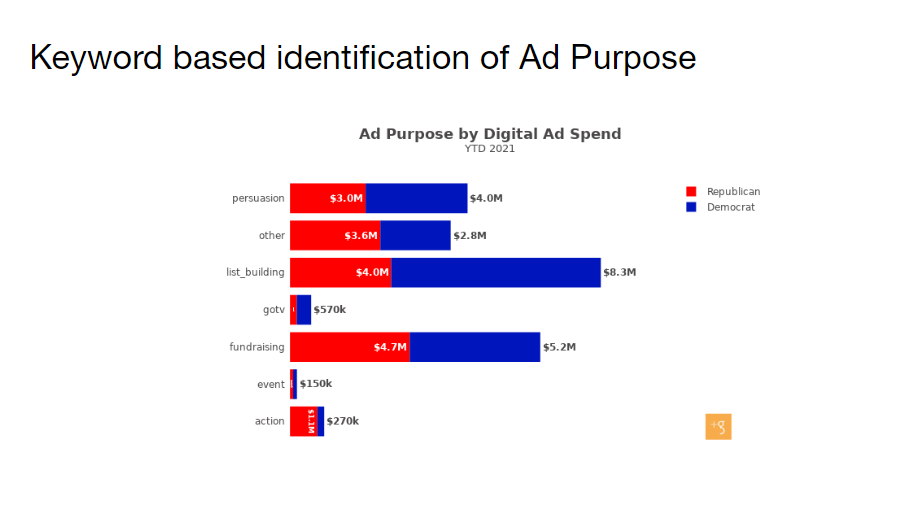
As a backup plan I had prepared a very simple NLP algorithm that simply counted the occurances of coded keywords. For example if “immigration” appeared in an ad’s text, we assigned the label of “immigration” to the ad’s topics. For this we needed to manually maintain a list of keywords, but this was much less expensive that hiring manual data coders. It could also be developed and implemented by an analyst. And unlike the machine learning model, it actually worked. We were able to do something similar with sentiment analysis using coded “positive” and “negative” keywords. We even were able to automatically categorize the purpose of ad based on both keywords and basic analysis of the landing pages the ads linked to.

When to use AI
Sometimes, however, simple classical techniques are not enough to obtain the results we need. AI is useful for the cleaning and processing of data where it doesn’t make sense to have a series of simple rules. In needing to get all our data into a basic text format for analysis, we had the problem of having many image, video, and audio ads that didn’t come with any easily readable text or captions. So I evaluated a few different models for processing and transcribing these formats and put them to work converting our data as it came in.
In addition, returning to the problem of emotional content of ads – many ads contain information that does not map to text at all. Ad copy like “Vote Now!” tells you some important information about the ad creative, but an ad is as much images and it is words. Even by processing all image, video, and audio from ads to extract the textual information contained within, we were still missing key points of information. So I decided to add a facial emotion recognition component to our pipeline.
I trained a basic model in Tensorflow on already existing public datasets, and used to assign a basic emotional context to ads just based off of the facial expressions in the ad creative.

Final Product
Once a reliable pipeline for ad level spend estimates and categorization has been established, one can easily answer a variety of questions about the current digital political ad environment:
- How much are conservative groups spending on immigration topics?
- How much money was spent on immigration related ads for certain period of time?
- What total reach did ads utilitizing ‘negative’ sentiments towards immigration have during a certain period of time?
At GMMB we ended up producing a variety of dashboards, alert triggers, automated emails, and APIs – all that were only possible due to time spent creating a reliable data pipeline. Our base dataset and assorted research tools were used by a variety of media groups and organizations such as BFP, the Kamala Harris campaign, DSCC, DCCC, DGA, Priorities USA, as well as in-house for GMMB digital campaigns.
Traditional Media
Traditional media (TV, Radio, etc.) is entirely another beast. Rather than a problem of web scraping, it was a problem of digitization. That can wait for another post.